사실 스스로도 Spring Batch(배치 애플리케이션)의 역할 및 기능을 알아보기 이전까지는 스케줄러 + 배치의 조합과 특정 스케줄러를 이용해 주기적으로 특정 API를 호출하도록 하는 것과의 차이에 대해 궁금해했었다. 이는 전적으로 배치에 대한 개념적인 이해의 부족이 초래한 결과이었는데, 사실 생각해 보면 어떤 반복 작업을 처리하기 위해 단순히 만들어 놓은 비즈니스 로직을 실행하기 위한 API 호출을 하는 것과 달리 배치 애플리케이션을 이용하는 것은 분명히 필요한 서비스 로직 외에 어떤 책임을 가지고 있을 거라 예상할 수 있다.
위에서도 거론했듯이 Spring Batch는 책임의 위임과 분리를 통해 우리는 어떤 대용량 일괄 처리를 위한 비즈니스 로직에 집중할 수 있게 하는 큰 장점을 제공한다.
어떻게 가능한 일일까? 사례와 함께 각 기능들을 살펴보자. 수천 개의 데이터에 대해 매일매일 과금액과 결제액을 대조해서 정산 결과를 반환해야 한다고 가정한다.
작업 동안 큰 데이터를 조회, 가공, 저장하다 보니 해당 처리가 많은 cpu, memory 자원을 사용하게 된다. 이로써 동일 시간대에 들어오는 외부 트래픽에 대한 처리가 어려워진다.
대용량의 처리를 진행하다 보니 중간에 처리가 실패할 수도 있다. 이때, 에러가 발생한 시점을 따로 관리하고 있지 않다면, 처음부터 다시 처리해야 한다. (반복 처리가 불가능할 수도 있다.)
위와 같이 반복 처리를 가능하게 하려면, 대용량 데이터 처리 실패 시 지금까지 진행된 모든 내용들이 롤백될 수 있도록 트랜잭션 범위를 잘 지정해 주어야 한다.
만약, 잘못된 요청으로 이미 성공적으로 진행된 내용에 대해 재시도를 요청하게 된다면, 데이터 정합성 등의 문제가 발생할 수 있으니 이미 성공한 파라미터에 대해서는 재시도하지 않도록 별도의 처리가 필요하다.
이렇듯, 대용량 데이터의 일괄 처리 작업에 있어서 위와 같이 부가적으로 신경 써야 하는 부분이 존재하고, 이는 개발자로 하여금 비즈니스 로직 구현에만 집중하는 것을 방해한다. Spring Batch를 이용하면 위와 같은 부가적인 작업들을 신경 쓰지 않고, 비즈니스 로직 구현에만 집중할 수 있다.
Spring Batch는 이것을 어떻게 가능하는 것일까?
실제로 위 내용들이 관리되는 데이터베이스 테이블들을 살펴보기에 앞서 간단하게 spring batch와 관련된 몇 가지 용어에 대해 알아보자.
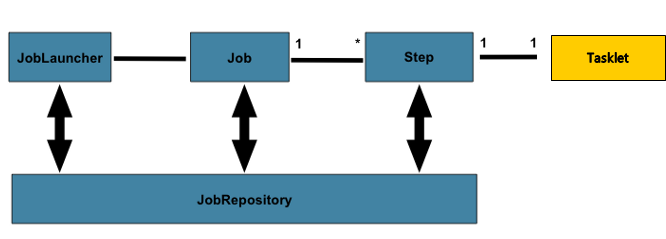
Job
Job은 배치 과정의 최상단 객체로써, 하나의 배치처리 실행 단위이다.
일반적으로 reader, processor, writer를 하나의 묶음으로 job을 구성한다.
또한, spring batch는 데이터베이스에 job 실행 정보를 관리함으로써 저장된 정보를 기반으로 batch job을 실행 제어할 수 있다.
Jobparameters
배치 실행 시점에 처리를 위해 넘겨주는 파라미터들을 의미한다.
지원 타입은 아래와 같다.
String
Long
Double
Date
Boolean
사실 이외에도 커스텀한 타입의 파라미터를 이용할 수 있으나 JobParamenter 객체의 Serailizer, Deserializer를 구현하여 넘겨받은 파라미터 객체를 string으로 변환해 줄 수 있고, 다시 객체로 변환해 줄 수 있어야 한다.
Jobinstance
특정 Job + Jobparameters의 조합으로 하나의 JobInstance 가 생성된다.
반드시 동일한 Jobparameters에 대해서는 동일한 JobInstance를 공유한다.
JobInstance 은 데이터베이스에 저장됨으로써 특정 파라미터를 넘겨받은 job의 실행 히스토리를 관리하는 특징이 있다.
Jobexecution
JobExecution 인스턴스 또한 관련 데이터가 데이터베이스에 저장돼 관리된다는 점에서 JobInstance와 같이 특정 Job의 실행 히스토리를 관리하는 특징을 가지고 있다.
단, JobExecution 은 JobInstance의 하위 개념으로서 JobInstance의 실행 결과가 누적된다. 즉, 해당 JobInstance의 실행 히스토리를 알 수 있다.
예를 들어보면, Job1 + 20200101 -> JobInstance 가 있다고 가정했을 때, JobInstance 자체는 그래서 해당 파라미터로 실행된 Job의 최종 결과만을 관리하지만, JobExecution는 JobInstance의 실행 수만큼 생성됨으로 최종 결과까지 몇 번의 실행과 어떤 상태를 거쳤는지에 대해 추적이 가능하다.
Spring Batch 가 관리하는 데이터베이스 테이블
이제, 관련해서 간단하게 Job을 생성해 보고, Job 실행의 성공과 실패 여부에 따라 어떤 테이블에 어떤 데이터가 적재되는지 알아보자. (글이 길어짐을 방지하기 위해 mysql 세팅 및 데이터베이스 생성과정은 생략한다.)
우선, spring batch의 사용을 위해선 아래와 같은 테이블들을 초기화시켜주어야 하는데, 크게 2가지의 방법으로 초기화 진행이 가능하다.
1. 스키마 생성 기능의 사용 스키마 생성 기능을 사용하려면, application.yaml 파일에 다음과 같은 설정을 추가해야 한다.
spring:
datasource:
url: jdbc:mysql://localhost:3306/spring_batch
username: root
password: -
# 추가되어야 하는 부분 #
#########################
batch:
jdbc:
initialize-schema: always
#########################
spring.batch.jdbc.initialize-schema: always의 값으로 설정해 주면, 자동으로 데이터 베이스에 필요한 테이블들을 초기화해 준다.
2. 스키마 생성 스크립트 실행 두 번째는 수동으로 필요 스크립트를 실행하는 방법이다. 각각의 벤더별로 schema-*. sql 파일을 찾아 해당 sql 문 안에 정의돼 있는 스크립트를 실행시켜 주는 방식이다. 나의 경우, mysql을 이용하니 schema-mysql.sql 에 정의돼 있는 스크립트를 실행시켜 주었고 정상적으로 필요한 테이블들이 생성되었다.
이제 spring batch 실행을 위한 세팅이 완료되었으니 실제로 spring batch 실행하여 값이 어떻게 각 테이블들에 누적되고 있는지 각 테이블들은 어떠한 역할을 가지고 있는지 알아보자. 아주 간단하게 테스트를 위한 simpleJob, simpleStep을 하나씩 생성하고 spring batch를 돌려보도록 하자.
(번외) @EnableBatchProcessing 은 spring batch를 사용하기 위해 반드시 선언해 주어야 하는 어노테이션이다. 해당 어노테이션을 선언하면, JobRepository, JobLauncher, JobRegistry, JobBuilderFactory, StepBuilderFactory 등의 빈들을 직접 등록해 주기 때문에 해당 빈들을 직접 등록해주지 않아도 사용할 수 있다. 만약 위 어노테이션을 선언하지 않고, 어떠한 빈 등록 처리도 진행하지 않았다면 아래의 코드에서 jobBuilderFactory, stepBuilderFactory 빈들의 생성자 주입이 불가할 것이다.
@Configuration
@EnableBatchProcessing
class BatchConfiguration(
private val jobBuilderFactory: JobBuilderFactory,
private val stepBuilderFactory: StepBuilderFactory,
) {
private val logger = LoggerFactory.getLogger(this::class.java)
@Bean
fun simpleJob(): Job {
return jobBuilderFactory["simpleJob"]
.start(simpleStep())
.build();
}
@Bean
fun simpleStep(): TaskletStep {
return stepBuilderFactory["simpleStep"]
.tasklet { _: StepContribution?, _: ChunkContext? ->
logger.info(">>>>> This is Step")
RepeatStatus.FINISHED
}
.build()
}
}
Job을 실행하고 나서 데이터 베이스 각 테이블에 어떤 값들이 초기화되었을까? 각 테이블의 ID를 생성하기 위한 BATCH_*_SEQ 시퀀스 테이블과 콘텍스트 정보를 저장하는 BATCH_*_CONTEXT은 제외한다.
BATCH_JOB_INSTANCE Job의 이름을 simpleJob으로 생성하여 실행하였더니, 아래와 같이 simpleJob을 JOB_NAME으로 갖는 JobInstance row가 하나 추가되었다. 즉, JobInstance를 저장 및 관리하는 테이블로 동일한 이름의 Job이 생성되지 않도록 하고, 넘겨받은 파라미터를 이용해 JOB_KEY(유니크 키)를 생성시켜 동일한 파라미터로는 복수의 JobInstance로 관리되지 않게 한다. 만약, Job1 + 20200101(params)의 조합으로 생성된 JobInstance 라면, 항상 동일한 JOB_KEY를 생성하므로 유니크 키인 JOB_KEY 컬럼의 특성상 동일한 Job, params 값에 대해선 중복으로 저장될 수 없다. (JobInstance로 생성되지 않음)
BATCH_JOB_EXECUTION 마찬가지로 JobInstance의 ID값을 참조하는 JobExecution 관련 row 도 추가되었고, 이는 JobExecution의 생성/실행/종료 시간과 성공 여부를 관리하는 테이블이다. 아래 내용과 같이 어떤 JobExecution 가 언제 실행 및 시작 그리고 종료되었는지에 대한 여부와 Excution의 실행 결과와 종료 코드에 대해 기록한다. 일반적으로 STATUS는 JobExecution의 실행 결과를 기록하고, EXIT_CODE는 JobExecution 종료 시점에 반환된 메시지 코드이다. 여기서는 COMPLETED로 기록됐지만, 모종의 이유로 중단된 상황에서는 중단 이유와 관련된 코드가 기록될 수 있다. (중단 관련 메시지는 EXIT_MESSAGE에 따로 저장된다.) 만약, 파라미터가 따로 없는 Job을 두 번 실행시켰을 경우, 아래의 결과와 같이 동일한 JobInstance ID를 갖는 JobExecution 이 하나 추가되었고, 이는 이미 완료된 JobInstance 로써 EXIT_CODE 가 NOPE로 반환되었다. 반면, JobInstance는 하나의 인스턴스만 생성된 결과를 확인할 수 있다.
BATCH_JOB_EXECUTION_PARAMS JobExecution에 대한 파라미터를 저장하는 테이블로써, 이번 테스트에서는 전달해 준 파라미터가 따로 없었기 때문에 어떠한 데이터도 추가되지 않았다. 이 테이블은 기본적으로 아래 데이터가 저장되어 관리되는데, 이를 통해 spring batch는 JobExcution 마다 어떤 파라미터를 가지고 실행되었는지 추적이 가능하다.
JOB_EXECUTION_ID: JobInstance의 실행 식별자
TYPE_CD: Job Parameter의 데이터 타입
KEY_NAME: Job Parameter의 이름
STRING_VAL: Job Parameter의 값
BATCH_STEP_EXECUTION step의 실행 정보가 담긴 테이블로써 특정 JobExecution을 참조한다. step의 시작, 종료, 각 종 상태를 저장해 관리한다.
step 내에서 관리하는 상태들은 Batch Job 실행 후 실패한 시점에 대한 파악과 롤백해야 하는 지점등에 대해서 관리할 수 있게 된다.
tasklet vs chunk
다음으로는 Job을 구현하는 방법에 대해 알아보자. Job을 구현함에 있어서 스프링 배치는 2가지 구현 방법을 제공한다. (위 예시 코드에서는 tasklet을 사용했다.)
tasklet
chunk
각각은 어떤 차이가 있을까?
tasklet
tasklet 은 step 안에 single task를 의미한다. 각각의 step은 tasklet을 구현하여 만들어진다. 예를 들면, 아래와 같이 예시 코드를 작성해 볼 수 있고, tasklet은 단일 함수로 이루어진 인터페이스이기 때문에 따로 클래스로 생성하지 않아도 익명의 함수로 만들어서 정의할 수 있다.
즉, chunk는 배치 작업의 특성상 특정 위치에서 데이터를 불러와 가공하고 다시 적재하는 작업이 주를 이루다 보니 위와 같은 읽는 작업, 가공 작업, 쓰는 작업을 하나의 chuckStep으로 묶어 Job의 step으로 지정한다. 또, chunk 형 step은 한 번에 처리할 수 있는 데이터의 양을 지정할 수 있는 특징이 있는데, 덩어리라는 표현이 이러한 기능에 기반하지 않았나 싶다. 위와 같이 chunk <String, String>(2) 형태로 표현했다면, 이는 한 번에 2개의 데이터를 처리하겠다는 의미가 된다.
어떻게 2개씩 처리할 수 있을까?
우선, chuck는 위에 예시 코드에 정의된 내용처럼 itemReader, itemProcessor, itemWriter의 조합으로 구성되는데 itemReader에서 chunk로 지정한 데이터 수만큼 데이터를 나누어 읽어드리게 된다.
예를 들어, 총 1000개의 데이터를 처리한다고 했을 때, chunk size를 100으로 지정했다면 Spring Batch는 ItemReader에서 100개씩 데이터를 읽고 각 Chunk에서 ItemProcessor와 ItemWriter를 적용한다. 단, 100개씩 데이터를 읽어드릴 때, 따로 batch query를 통해 I/O 작업을 좀 더 최적화시키기보다는 JdbcCursorItemReader를 이용하여 한 번에 한 행씩 총 100개를 읽어드리게 된다.
그래서 대용량 데이터 처리 시, chuck와 함께 itemReader 내에서 paging 처리를 따로 해주게 되면, 성능을 크게 향상할 수 있다. chunk size만큼 처리되어야 하는 데이터를 한 번에 가져올 수 있기 때문이다. 또한, chuck 사이즈와 paging 사이즈를 일치시킨다면, 한 번에 트랜잭션 내에 불필요하게 복수의 읽기 쿼리가 실행되는 상황을 예방할 수 있고 이는 성능을 극대화시킬 수 있다. spring batch는 적절한 paging/chunk size에 대해 아래와 같이 설명하고 있다.
Setting a fairly large page size and using a commit interval that matches the page size should provide better performance. 페이지 크기를 상당히 크게 설정하고 페이지 크기와 일치하는 커밋 간격을 사용하면 성능이 향상됩니다.
(번외) JdbcCursorItemReader는 읽어온 데이터에 대해서는 커서를 이동시키는 방법으로 이전의 결과를 메모리에서 유지할 필요 없이 한 행씩 읽어 처리하는 것이 가능하다. 이러한 처리는 메모리 사용량을 보장할 수 있으며, 전체적인 성능도 향상하는 장점이 있다.
chuck 지향 처리로 얻는 장점은 무엇이 있을까?
chuck 단위로 트랜잭션처리가 되기 때문에 450번째의 데이터 진행 중 실패 시, 앞선 300개 까지는 롤백처리가 진행되지 않아도 되며, 400번째부터 재시도가 가능하다.
또, 한 번에 1000개의 데이터를 모두 메모리에 불러들이지 않기 때문에 동일 양의 데이터를 처리한다고 하더라도 훨씬 적은 양의 메모리 사용이 가능하다. 그래서 대용량의 데이터를 처리할 때, OutOfMemoryError 등의 문제를 예방할 수 있다.
Spring Batch과 배치 실행과 함께 관리하는 테이블들과 Job을 구현하는 2가지 방법을 알아봄으로써 Spring Batch 가 어떻게 개발자들이 비즈니스 로직 구현에만 집중하게 할 수 있는지에 대해 알아본 시간이었다.
다음 글에서는 Spring Batch 테스트 방법과 Spring Batch Plus에 대해 좀 더 알아보려고 한다.



 일반적으로 STATUS는 JobExecution의 실행 결과를 기록하고, EXIT_CODE는 JobExecution 종료 시점에 반환된 메시지 코드이다. 여기서는 COMPLETED로 기록됐지만, 모종의 이유로 중단된 상황에서는 중단 이유와 관련된 코드가 기록될 수 있다. (중단 관련 메시지는 EXIT_MESSAGE에 따로 저장된다.) 만약, 파라미터가 따로 없는 Job을 두 번 실행시켰을 경우, 아래의 결과와 같이 동일한 JobInstance ID를 갖는 JobExecution 이 하나 추가되었고, 이는 이미 완료된 JobInstance 로써 EXIT_CODE 가 NOPE로 반환되었다.
일반적으로 STATUS는 JobExecution의 실행 결과를 기록하고, EXIT_CODE는 JobExecution 종료 시점에 반환된 메시지 코드이다. 여기서는 COMPLETED로 기록됐지만, 모종의 이유로 중단된 상황에서는 중단 이유와 관련된 코드가 기록될 수 있다. (중단 관련 메시지는 EXIT_MESSAGE에 따로 저장된다.) 만약, 파라미터가 따로 없는 Job을 두 번 실행시켰을 경우, 아래의 결과와 같이 동일한 JobInstance ID를 갖는 JobExecution 이 하나 추가되었고, 이는 이미 완료된 JobInstance 로써 EXIT_CODE 가 NOPE로 반환되었다.  반면, JobInstance는 하나의 인스턴스만 생성된 결과를 확인할 수 있다.
반면, JobInstance는 하나의 인스턴스만 생성된 결과를 확인할 수 있다.