SQS 적용 과정에서 아래와 같은 중복 수신 상황을 다룬 과정을 소개하려고 한다.
아래와 같이 동일한 바디(Message Body)를 가진 메세지를 중복하여 수신할 수 있는 상황이 존재한다.
- Source Queue 에서 처리 완료되지 못한 메세지를 MaxReceiveCount 만큼 재시도한다.
- 메세지 처리 불가 상태로 추정되어 DLQ 로 이동된 이후에 재시도된다.
메세지가 Visibility Timeout (가시성 타임아웃) 내에 정상적으로 처리되지 못하여 재시도되는 상황은 다음과 같다.
- 메세지 처리시간이 Visibility Timeout 을 초과할 경우
- 메세지 처리 중, 예외가 발생했을 경우
재시도 상황 1
설명에 앞서, Visibility Timeout 이 무엇이고, 어떻게 동작하는 것이며, Visibility Timeout 시간을 초과한 경우가 문제가 되는 이유에 대해 살펴보자.
Visibility Timeout?
가시성 타임아웃 이라고도 불린다. 일반적으로 Visibility Timeout 자체가 기본적으로 SQS 의 중복 요청을 방지하는 역할을 가지고 있다.
이 가시성 타임아웃은 어떻게 중복 요청을 방지할 수 있는지 1) AWS SQS의 기본적인 아키텍처와 2) 메세지 라이프 사이클을 간단하게 살펴보자.
SQS Architecture

각 시스템에서 메세지를 생성 및 전달하는 Producer 의 존재가 있고, 수신한 메세지를 SQS 에서는 분산된 서버들에 중복해서 저장하고 있는다.
중복 저장은 메시지의 안정성, 가용성, 성능, 복구 기능을 향상시키는 데 도움을 주며, 대규모 분산 시스템에서 일반적으로 채택되는 방법이기 때문에 동일한 이유로 메세지를 여러 서버에 분산해 저장하고 있다고 생각해 볼 수 있다.
Message LifeCycle

- Component 1(producer)에 의해 메세지 A 가 큐로 보내지고, 메세지는 여러 서버에 분산되어 저장되게 된다.
- Component 2(consumer)에 의해 메세지 A가 소비되고, Visibility Timeout 으로 설정한 시간 동안 다른 Consumer 에 의해 소비되지 못하도록 가려진다.
- Visibility Timeout 시간 동안 처리 완료된 메세지 A는 큐로부터 삭제되고, Component 2 를 제외한 다른 Consumer 는 메세지 A를 처리하지 못한다.
- 단, Visibility Timeout 시간 동안 메세지 A가 삭제되지 않는다면, Visibility Timeout 이 초과한 후에는 다시 다른 Consumer 가 메세지 A를 소비할 수 있게 된다.
메세지는 여러 서버에 분산되어 저장되어 있으나, Visibility Timeout 으로 설정한 시간동안 다른 Consumer 가 처리 중인 메세지를 소비하지 못하도록 막음으로써 메세지 중복 처리를 예방할 수 있게 된다.
허나, 4번 내용대로 만약 Visibility Timeout 시간 동안 메세지 A가 삭제되지 않는다면, 첫번째로 메세지를 수신한 Comsumer 가 해당 메세지를 처리 중이더라도 다른 Consumner 가 해당 메세지를 수신할 수 있게 되는 상황이 발생하게 된다.
그럼, Visibility Timeout 값을 아주 길게 잡으면 되지 않을까? 라고 생각할 수 있으나 이는 해당 메세지를 처음 수신한 Consumer 가 모종의 이유에 의해 메세지 처리에 실패하고, 이를 반환하지 못하는 경우(해당 Consumer의 문제), Visibility Timeout 시간동안 다른 Consumer 가 해당 메세지를 처리하는 것을 막게됨으로써 메세지의 처리 시간을 증가시킨다.
또한, Visibility Timeout 시간 동안 처리되지 못한 메세지들이 서버 내에 계속해서 남아있게 됨으로써 성능 저하 및 전체 메세지의 처리 지연을 가져오게 된다.
결론적으로
- Visibility Timeout 이 완벽하게 메세지 중복 수신을 예방할 수 있는 것은 아니며
- Visibility Timeout 무작정 충분한 값으로 설정하는 것은 전체 성능에 좋지 않은 결과를 낳을 수 있기 때문에 Visibility Timeout 을 적절한 값으로 타협을 보되, 메세지 처리 함수가 "멱등성"을 보장하도록 구현해야 한다는 결론에 이르렀다.
Spring Boot Cache Manager 로 멱등성 보장하기
멱등성을 구현할 수 있는 여러 방법이 있겠으나, 우선 메세지 처리 로직 외에 메세지 멱등성 보장을 위한 다른 로직이 추가되는 상황을 방지하고자 했고, Spring Boot CacheManager 를 이용해 다음과 같이 어노테이션으로 각 메세지 식별자 값(Message ID)으로 응답값을 캐싱할 수 있도록 구현했다.
위 아키텍쳐에서 설명한 내용대로 중복 요청되는 메세지는 메세지가 새롭게 생성되는 것이 아니라 기 저장된 메세지가 다시 소비 가능한 상태로 변경되는 것이기 때문에 메세지 별 식별자 값(Message ID)은 첫 요청 메세지와 동일하다. 그래서 Message ID 기반 캐싱이 가능한 것이다.
@Cacheable(value = ["serviceName"], key = "#messageId")위와 같이 설정을 해준다면, 이미 동일한 Message ID Key 값으로 처리된 이력이 있을 때, 내부 로직을 태우지 않고 저장된 결과값을 그대로 반환한다.
간단한게 구현한 내용은 아래와 같다. 주석에 적어 놓은 내용과 같이 만약 캐싱이 되었다면,
동일한 Message ID 값에 한해서 내부로직을 중복해서 타지 않고, 이미 반환된 결과값과 동일한 결과값을 반환해야 한다.
아래 테스트는 중복 수신을 발생시키기 위해 SQS 설정은 아래와 같다.(이외 값 기본 설정)
추가적으로 스레드를 5s 간 지연시킨다.
- Visibility Timeout: 3s
- MaxReceiveCount: 2// SQS 리스너 구현부
@SqsListener(value = ["\${cloud.aws.sqs.testQueue}"], deletionPolicy = SqsMessageDeletionPolicy.ON_SUCCESS)
fun receiveStringMessage1(
message: String?,
@Headers header: Map<String, String>,
@Header("MessageId") messageId: String,
@Header("ReceiptHandle") receiptHandle: String,
) {
logger.info("message: $message, messageId: $messageId")
val random = cacheService.testService(messageId)
logger.info("message: $message, ret: $random")
sqsAsyncClient.deleteMessageAsync("\${cloud.aws.sqs.testQueue}", receiptHandle)
}
// 서비스 로직 구현부
@Service
@CacheConfig
class CacheService {
@Cacheable(value = ["serviceName"], key = "#messageId")
fun testService(messageId: String): String {
// 시간 지연을 둔다. Visibility Timeout 보다 크게 설정해 중복 수신 상황을 발생시킨다.
Thread.sleep(5000)
// 캐싱이 된다면, 처음 요청과 동일한 random string 값을 반환할 것이다.
return UUID.randomUUID().toString()
}
}결과
실제로 4번째 메세지의 경우 동일한 응답값을 반환하는 것을 확인할 수 있다.

분산환경에서 Spring Cache
하지만, 분산환경에서 Spring Cache Manager를 적용하기위해서 하기 2가지에 내용에 대한 확인이 필요하다.
- Spring Boot 기본 Cache Manager
- 동일 Key 값에 대한 동시성 보장
1. Spring Boot 기본 Cache Manager
Spring Boot Cache 는 ConcurrentMapCacheManager 를 기본 CacheManager 로 지정한다. 하지만, ConcurrentMapCacheManager 는 내부적으로 ConcurrentHashMap을 사용하여 캐시를 관리하는 메모리 기반 캐시 매니저로써 분산환경에서의 사용이 적합하지 않다. 분산환경에선 각각의 Pod 들이 독립적으로 별도의 메모리에서 캐시를 관리하게 되기 때문에 하나의 Key 값에 반드시 한번의 처리를 보장할 수 없게 되기 때문이다.
결과적으로 하나의 MessageID에 대해 반드시 한번의 처리만 보장하게 하기 위해선 서로 다른 Pod 들이 하나의 Redis 서버에서 캐시를 관리할 수 있도록 RedisCacheManager 를 이용해 CacheManager 를 구현할 필요가 있다. (Redis cache manager 를 이용한 세부 구현은 생략한다.)
2. 동일 Key 값에 대한 동시성 보장
Redis 를 이용해 응답값을 캐싱해 관리할 때, Redis 에 해당 Key-value 가 저장되는 시점은 메세지 처리 요청에 대한 응답 시점이다. 즉, 첫번째 메세지 수신 서버가 메세지 처리 시간이 지연되어 응답이 늦어지는 경우, 처리 중간에 중복 수신이 발생한다면 기대한대로 캐싱이 되지 않는다.
위와 같은 문제는 기본적으로 RedisCacheManager 또한 내부적으로 ConcurrentHashMap을 사용하여 캐시를 관리하기 때문에 단일 서버에선 동일한 Key 값에 대한 동시성 관리가 가능할 수 있으나, 분산환경에는 첫번째로 메세지를 수신한 Pod의 처리가 지연되는 경우, 다른 Pod 가 메세지를 재수신하여 처리를 진행하게 되기 때문에 발생한다.
결과적으로 동일한 키 값에 대해서는 지정한 임계구역 내에서 항상 동일한 응답값을 반환받을 수 있도록 내부적으로 분산락을 구현하여 동일 Key 값에 대해서는 첫번째 처리가 완료된 뒤, 두번째 처리가 진행될 수 있도록 해야 한다.
분산락 또한 Redisson 라이브러리를 이용해 용이하게 구현할 수 있는데, 아래와 같이 구현하여 동일한 Message ID 에 대한 두번째 요청은 캐싱된 내용을 반환받을 수 있도록 하였다.
기본적인 분산락에 대한 적용과 개념은 아래 글을 확인해 보길 바란다.
> Redis 분산락을 이용해서 한 번에 한 번씩 결제하기
@SqsListener(value = ["\\${cloud.aws.sqs.testQueue}"], deletionPolicy = SqsMessageDeletionPolicy.ON_SUCCESS)
fun receiveStringMessage(
message: String?,
@Headers header: Map<String, String>,
@Header("MessageId") messageId: String,
@Header("ReceiptHandle") receiptHandle: String,
) {
logger.info("message: $message, messageId: $messageId")
// 분산락 구현
val random = redisClient.lockMessageIdForTest(messageId) {
// 임계구역
cacheService.testService(messageId)
}
logger.info("message: $message, ret: $random")
sqsAsyncClient.deleteMessageAsync("\\${cloud.aws.sqs.testQueue}", receiptHandle
)
}
@Cacheable(value = ["serviceName"], key = "#messageId")
@Transactional(timeout = LEASE_TIME)
fun testService(messageId: String): String {
// 캐싱이 된다면, 처음 요청과 동일한 random string 값을 반환할 것이다.
return UUID.randomUUID().toString()
}
}
분산락 설정
/**
너무 오래 대기하지않고, WAIT_TIME 을 초과하면 락 점유 실패 예외를 반환해
SQS 자체적으로 메세지 처리 실패로 간주하고 재시도 하게끔 설정한다.
*/
- WAIT_TIME = 5L
/**
해당 로직이 수행되는 시간보다 기본적으로 쿠션 타임을 좀 더 두고 설정한다.
해당 값은 트랜잭션에 설정 해둔 timeout 시간과 동일하게 설정한다.
해당 타임아웃 시간이 초과되면, 1) 락 해제 2) 처리된 모든 내용이 롤백 3) 캐싱 X
=> 재시도가 가능한 상태를 유지한다.
*/
- LEASE_TIME = 해당 로직이 수행되는 시간 + 쿠션 타임
// 재시도 횟수
- ReceiveCount = 10
재시도 상황 2
수신 메세지 처리 중 예외가 발생한 경우에는 트랜잭션을 처리 로직 최상단에 걸어서 처리한 모든 내용을 무조건 롤백되도록 한다.
기본적으로 자바 표준 트랜잭션을 사용하게 되면 Checked Exception 이 발생했을 때, 트랜잭션 롤백이 정상적으로 동작하지 않기 때문에 아래와 같이 rollbackFor 를 지정해 줌으로써 모든 예외에 대해 롤백이 동작할 수 있도룩 한다.
import javax.transaction.Transactional
@Transactional (rollbackFor = Exception.class)반면, 스프링 프레임워크에서 제공하는 트랜잭션은 모든 예외 상황에 대해 기본 롤백을 지원한다.
그래서 따로 예외 클래스를 지정해 주지 않고, 아래 처럼만 정의해도 예외 발생 시 롤백이 된다.
import org.springframework.transaction.annotation.Transactional
@Transactional(timeout = LEASE_TIME)어떤 방식으로든 롤백 처리를 하게 되면, 몇번이고 중복 처리를 시도하더라도 결과적으로는 마지막으로 정상 동작한 한 번의 결과만 남게된다.
위와 같은 케이스들은 DLQ 로 이동시켜, 실패 케이스들에 대해서만 디버깅할 수 있도록 한 뒤, 메세지를 정상적으로 소비할 수 있도록 수정하고, 재시도가 되도록 한다.
Dead Letter Queue 의 생성
모든 메세지들이 정상적으로 소비되고, 삭제되면 좋겠으나 모종의 이유로 메세지가 처리되지 못하고, 계속해서 소비되길 시도하는 메세지들이 존재할 수 있다.
이런 메세지들을 모두 한대 묶어 하나의 큐에서 관리된다면, 1) 다른 메세지들과 섞여 메세지 관리도 힘들 뿐만 아니라 2) 처리되지 못하는 메세지의 반복적인 소비 시도에 의해 다른 메세지의 요청 지연을 발생시킬 수 있다. 한 두건이면 문제가 크지 않겠으나, 관리되지 못한 메세지들은 계속해서 쌓이고 쌓이게 될 것이다.
그래서 이러한 메세지를 별도에 큐에서 관리할 수 있도록 SQS 는 Dead Letter Queue(DLQ) 라는 별도의 명칭을 가진 큐를 지원하고있다. 큐의 생성방식은 Source Queue와 차이가 없으나, 1) 생성한 DLQ를 Source Queue의 DLQ로 연결시켜 놓으면, 메시지의 ReceiveCount가 대기열의 MaxReceiveCount(사용자 지정 값)를 초과하게 될 때, Amazon SQS는 메시지를 연결된 DLQ(원래 메시지 ID 포함)로 이동시킨다. 2) 또한, DLQ 의 리드라이브 허용 정책에 Source Queue를 추가해줌으써 어떤 Source Queue의 DLQ로 사용할 것인지를 식별할 수 있도록 한다.
1) Source Queue 에 DLQ 연결
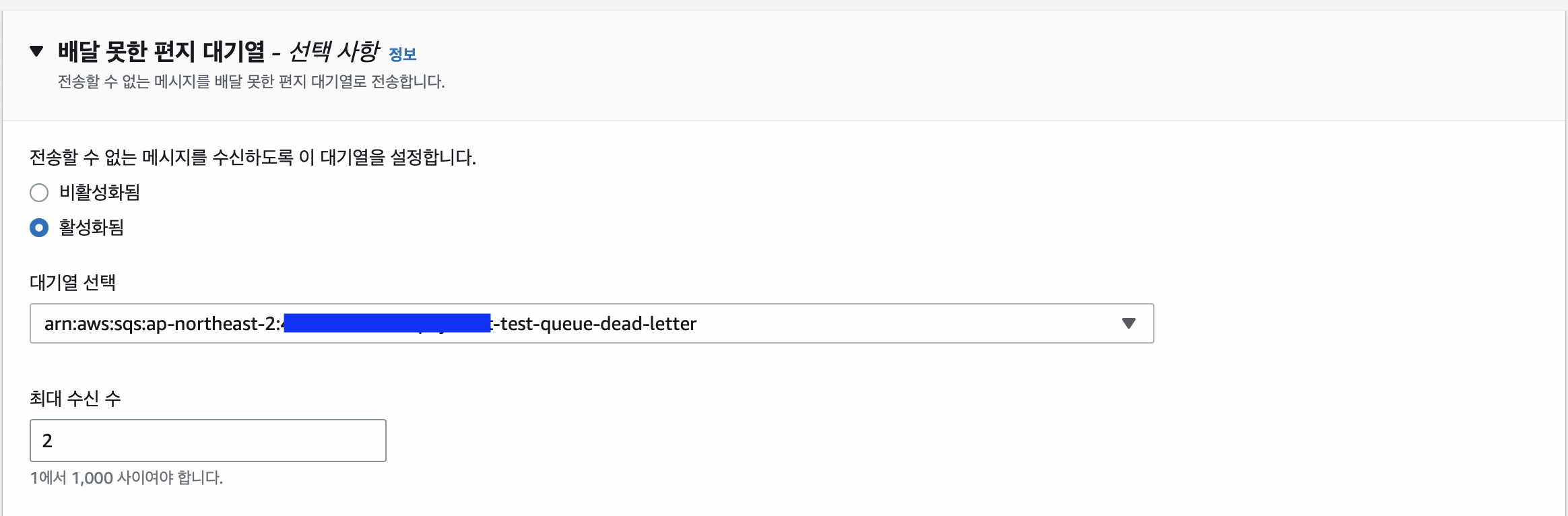
2) DLQ 에 리드라이브 정책에 Source Queue를 추가

하기 이미지는 실제 소비되지 않은 메세지들이 MaxReceiveCount 만큼의 Retry 시도 후에도 처리 완료되지 못하고, DLQ 에 쌓인 모습이다. 수신 수는 DLQ 로 해당 메세지들을 옮겨 오기 이전에 시도한 횟수를 그대로 가져온다.
단, 메세지 처리가 Visibility Timeout 를 초과하여 완료되는 경우, 적절하게 1) Visibility Timeout, 2) MaxRecieveCount 를 설정해 불필요하게 DLQ 로 메세지가 이동하는 것을 예방할 필요가 있다.
하기 이미지처럼 처리완료 되지 못한 메세지들이 DLQ 로 옮겨온걸 확인할 수 있다.

처리 실패한 메세지들에 대해 메세지 본문 및 속성값들의 확인을 통해 실패 원인을 분석할 수 있게된다.
DLQ 를 어떻게 소비하게할 수 있을까?
기본적으로 DLQ 에 담긴 내용을 소비하게 하기 위해선 해당 큐를 소비하는 리스너를 하나 더 추가하고, 동일한 로직을 태우게 하는 방법이 있을 수 있다.
하지만, 모종의 예외 상황에 의해 수신이 완료되지 않고, DLQ 로 옮겨온 메세지가 관련 내용이 수정되지 않은 채로 동일한 요청에 대한 처리 시도를 지속하는 건 의미없는 작업이 될 수 있다. 물론, 원인 분석 및 내용 수정 이후에 DLQ 리스너를 새롭게 붙이는 작업을 진행할 수 있으나 이 또한 코드 수정 작업이 수반된다.
AWS는 DLQ 리드라이브를 이용해 이런 번거로움을 개선할 수 있도록 지원한다.
DLQ 리드라이브는 하기 처리 내용 중 3번의 역할을 담당한다. 애플리케이션을 복구한 후에 DLQ의 메시지를 소스 대기열 또는 다른 사용자 지정 대상 대기열로 쉽게 리드라이브하도록 지원함으써 DLQ 용 리스너를 따로 열어두지 않아도 Source Queue로 메세지를 이동시켜 해당 Queue 에서 처리될 수 있도록 한다.
- Dead Letter Queue 에 쌓인 메세지들에 대해 디버깅 완료
- 어플리케이션 수정 및 복구
- Dead Letter Queue -> Source Queue 로 리드라이브
- Source Queue 의 consumer 에 정상 처리 완료
DLQ 리드라이브 -> 리드라이브 대상 선택(소스 대기열로 리드라이브) -> DLQ 리드라이브 클릭하면 Source Queue 로 리드라이브된다.


하지만, 이 때 유의할 점이 있다. 바로 리드라이브 된 메세지들은 새롭게 생성되기 때문에 리드라이브 되기 전, 보유하고 있던 식별자 값(Message ID)을 가져오지 않는다.
즉, 리드라이브된 메세지들은 식별자 값이 새롭게 생성되며, 이는 메세지를 수신하는 쪽에서 캐싱되지 않는다.
결과적으로 리드라이브된 메세지들은 반드시 기 롤백 처리되어 재수신이 필요한 메세지(재수신 상황 2)에 대해서만 DLQ 로 이동해야 함을 의미한다.
결론
재시도 상황 1
- Case
- 동일한 MessageID 의 메세지로 재시도
- Solution
- Spring Cache Manager
재시도 상황 2
- Case
- 모든 예외 상황
- Transactional Timeout
- Solution
- DLQ, Source Queue 리드라이브
'Spring' 카테고리의 다른 글
| RateLimiter 제대로 알고 쓰기 (0) | 2023.04.12 |
|---|---|
| RunTest에 대해서... (0) | 2023.03.26 |
| Redis 분산락을 이용해서 한 번에 한 번씩 결제하기 (0) | 2023.03.20 |
| I/O 작업 비동기로 처리하기(w. 코루틴) (0) | 2023.03.12 |
| Spring Batch - Job은 정말 실패한 시점부터 재실행될 수 있을까? (0) | 2023.03.05 |